meta data for this page
Project Basics
1. To start a project, click the “new” project button at the top.
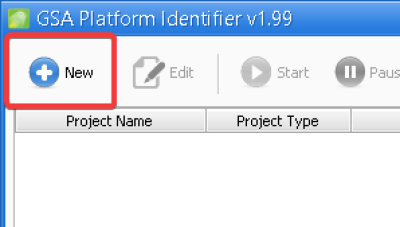
2. Now you can begin to configure your project. First, select the type of project you want to create.

Process files – Sort and identify URLs based on engine type, language, keywords, and much more. Multiple folders containing .txt files can be imported.
Monitor Files/folders – This option works just like the process files option, except it automatically checks the file/folder for new URLs to process. Simply set a folder, choose a countdown interval (E.G., 15 minutes) and every x amount of time, the software will check for new URLs to process.
Note to Scrapebox Users - By default, Scrapebox “locks” files while scraping URLS making folder/file monitoring impossible. We have been notified that this issue can be solved by using the Scrapebox Automator plugin.
Remove Duplicates – Automatically monitors specific folders/files that you want to automatically deduplicate. Simply set a folder, choose a countdown interval (E.G., 15 minutes) and every x amount of time, the software will check and remove duplicates from the .txt files in that folder.
3. Choose how you would like the project to be saved.
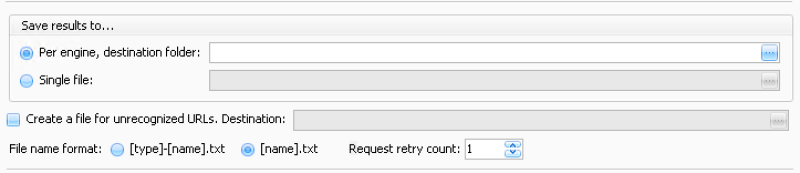
Per engine, destination folder – Sorts everything into individual files categorized by engine type. (Choose this option if building lists for GSA Search Engine Ranker)
Single File – Sorts and saves everything to a single file.
Create a file for unrecognized URLs. Destination – All URLs that do not match any engines or filters will be saved to this folder.
Max OBL - Filter out URL’s that have too many outbound links on the page. When a page/domain has too many outbound links, it can be seen as “spammy” and less link juice is passed to your link, this filter helps to filter out those heavily spammed pages/domains.
4. Select engines types and filters.
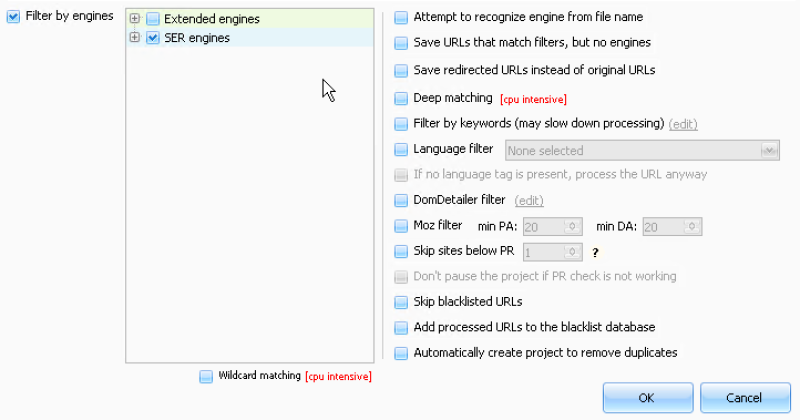
Filter by engines – Here you can select which types of engines you want to sort by. For Search Engine Ranker users, selecting only the SER Engines category is recommended. Extended engines require more resources due to a different detection method and are not necessary when building a site list for Search Engine Ranker.
Wildcard Matching – Slightly improves detection for some engines but is more CPU intensive.
Deep Matching – Slightly improves detection for some engines but is more CPU intensive.
Filter by keywords –Useful for finding niche-relevant websites. The keyword filters help filter out non-relevant URLs, by keeping only the URLs that feature your specific keywords in the title, URL, meta description, meta keywords, or page title.
Language Filter – Filter websites by language.
Domdetailer filter – Filter domains by Moz DA (Domain Authority), PA (Page Authority), Trust, Majestic CF (Citation Flow), TF (Trust Flow), and more. Domdetailer API key required. Add API key in settings before enabling this option.
Moz filter – Filter domains by minimum Moz PA (Page Authority) and DA (Domain Authority). Moz API required. Add API key in settings before enabling this option. Domdetailer API is a much more budget-friendly option and is recommended over Moz API.
Skip sites below PR – Unfortunately, Google no longer publicly displays Page Rank. In order to use this option, GSA PREmulator or GSA Proxy Scraper are required to “emulate” Page Rank.
Skip blacklisted URLs – Any URLs that have been added to the blacklist will be ignored and not processed.
Add processed URLs to the blacklist database – All processed URLs are automatically added to the database.
Automatically create project to remove duplicates – When this option is selected, a remove duplicates project is automatically created and will remove duplicates from the destination folder.
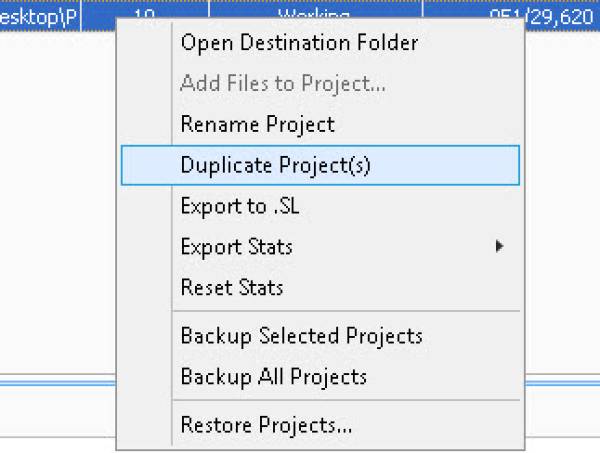
NOTE - Additional options can be found by right-clicking on a project. Here you can duplicate projects, export your project in .SL format (site list format used for GSA Search Engine Ranker), or backup and restore projects.